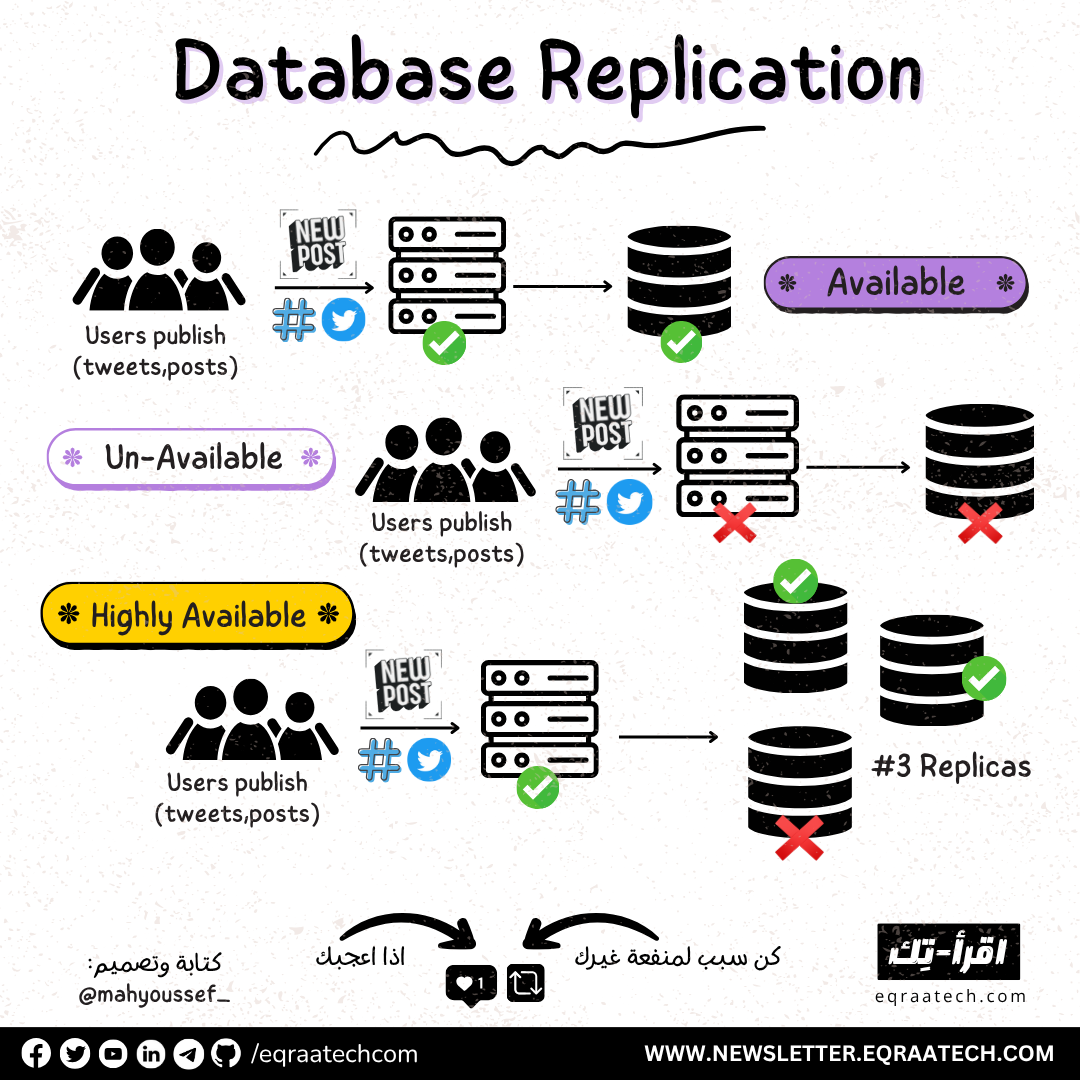
خلونا نتخيل كده مع بعض على سبيل المثال ان عندنا Service دورها بكل بساطة انك لما تيجي تكتب Post أو Tweet وتيجي تعمله Publish فالـ Service بتاخد الكلام ده وتحطه في الـ Database .. ولما تيجي تفتح الـ Profile بتاعك أو لحد من الناس فانت بتكون مستني انك تشوف الـ Posts أو الـ Tweets اللي في الـ Profile ده ..
الـ Service دي بتتعامل مع الـ Database بشكل أساسي عشان تقدر تـ Fetch الـ Data لما تيجي تشوف الـ Posts أو الـ Tweets وبتـ Write Data لما الناس تيجي تعمل Publish ..
الدنيا كانت ماشية كويس لحد ما في لحظة معينة ولسبب ما .. حصل مشكلة في الـ Database .. السبب هنا ليه احتمالات كتيرة مش هنتطرق ليها .. بس نتيجة ده ايه الي هيحصل ؟
Single Point of Failure
الـ Service هتقع .. وده لانها اصبحت مش عارفة تـ Fetch البيانات ولا انها تـ Write في الـ Database .. ودي بنسميها عندنا في الـ Distributed Systems .. مشكلة في الـ Availability بتاعة الـ Systems وبالأخص الـ Single Point of Failure .. وده معناه انك عندك جزء في الـ System لو وقع .. النظام ككل هيقع ومش هيقدر يؤدي دوره بالشكل المطلوب .. يعني مش Highly Available
طب كان حل المشكلة دي ايه ؟
الناس قالوا بدل ما يكون عندنا Database واحدة شايلة البيانات كلها .. خلونا ناخد “نسخ متماثلة” من الـ Database دي .. فيكون عندنا أكتر من واحدة وليكن (3) .. والـ 3 نسخ دول هيكونوا متماثلين وشايلين نفس البيانات بالظبط .. بحيث لو حصل مشكلة في واحدة .. فيكون لسه عندنا 2 .. وبكده نضمن ان لو حصل اي مشكلة في اي وقت للـ Database الـ System هيفضل مكمل شغل وبيؤدي دوره بشكل كويس ..
Replication
وهو ده الـ Replication اني اعمل نسخة متماثلة واكررها فيكون عندي اكتر من نسخة بدل نسخة واحدة .. وده طبعا فادنا كتير في الـ Distributed Systems من حيث الـ Availability وكمان الـ Scalability .. فلو عندنا الـ Service بيحصل عليها عمليات قراءة كتير فبدل ما اكون عندي Database واحدة بتاحد كل الـ Requests دي وترجع نفس الـ Data .. أصبح ممكن يبقى عندي الحمل متوزع على X Numbers of Database Instances شايلين نفس البيانات ..
أنواع الـ Replication
وهنا نيجي باه لنقطة مهمة وهي ايه انواع الـ Replication ؟
عندنا نوعين من الـ Replication , وهم :
- الـ Pessimistic Replication
- الـ Optimistic Replication
Pessimistic Replication
الـ Pessimistic Replication ده هدفه الاساسي انه يضمن الـ Consistency بين الـ Database Instances وبعضها في اي لحظة زمنية , وعشان كده من اسمها فهي متشائمة .. فلما الـ Service هتيجي تكتب في الـ Database اي حاجة .. النوع ده من الـ Replication عشان متشائم .. هيكون دايما خايف ان البيانات متكونش زي بعض في اي وقت من الأوقات ..
وهيعمل ايه ؟
كل اما الـ Service تيجي تكتب في الـ Database .. مش هيـ Acknowledge ان الـ Write تم بشكل سليم وان الـ Operation Succeeded .. الا لما يتاكد ان عملية الـ Write حصلت على باقي الـ Database Instances وان البيانات اتكتبت فيهم كلهم .. ولو حصل مشكلة في واحدة منهم بس .. هيعتبر العملية كلها انها Failure .. ( يا نعيش عيشة فل ، يا نموت احنا الكل )
Optimistic Replication
الـ Optimistic Replication هو نوع متكاسل شوية وهو ده الشائع في الـ Distributed Systems .. بيعتمد انه عارف ان في نفس اللحظة الزمنية هيكون فيه اختلاف في البيانات وانها مش كلها متسقة ومش كلهم شبه بعض .. بس متأكد ان في النهاية البيانات كلها هتبقى زي بعض .. وده بيكون اسمه Eventual Consistency .. طب امتة ده هيحصل ؟ ممكن بعد ثواني او بعد دقائق .. مش مشكلة .. بس المهم ان في النهاية كل البيانات هتبقى زي بعض ..
أي النوعين اختاره وأعتمد عليه؟
ده بيكون على حسب الـ Requirements بتاعة الـ System اللي بتبنيه .. وكل نوع ليه الـ Trade-offs الخاصة بيه .. على سبيل المثال الـ Pessimistic بيكون كويس في ضمان الـ Consistency ولكن هيأثر في الـ Write Throughput وعلى النقيض الـ Optimistic كويس جدا انه يديك Write Throughput عالي زي تطبيقات الـ Social Media اللي بيكون فيها ملايين الناس بتكتب في نفس الوقت .. بس في نفس الوقت انت بتضحي هنا بالـ Consistency .. فمش كل الناس هتشوف نفس الـ Posts او الـ Tweets في نفس الوقت .. ممكن حد يشوفها قبل كده بس في النهاية الكل هيشوفها ..